Performance Assessment using the
Whetstone v1.2 Benchmark on the Xilinx ML507 FPGA
Platform
Overview
Test Setup
Hardware Architecture
Clocking
Infrastructure
Glossary
The Whetstone Benchmark
IBM PowerPC Performance Libraries
Test Results
Measurement Results
w/ FPU
Measurement Results
w/o FPU
Inter-/Extrapolated Results
Summary & Conclusions
References
Well, I'm aware of the paraphrase 'fake, lie, benchmark', therefore I seek to follow best practices by clearly specifying the overall setup employed including hardware system, software and compiler versions used, and employed compilation flags. Moreover, I do not intend to tweak any system specifics in order to reach highest scores, but rely on ordinary compiler flags such as '-O2' and '-O3'. The corresponding results are listed below. Any interpretation is left to the prospective reader.
Note that in general, benchmark numbers are meaningless
without proper specification of compiler settings and
benchmarking conditions.
Last but not least, keep in mind Dilbert:
| Hardware | IBM PowerPC 440 CPU running at 400
MHz double-precision floating-point unit (FPU) running at 200 MHz CPM & PLB running at 133 MHz Peripherals: 32 kB BRAM, RS232 UART, interrupt controller, timer |
| Software | Whetstone benchmark version 1.2 (Language:
C) [5] Selected tests employ the IBM PowerPC Performance Libraries [6] |
| Compiler | powerpc-eabi-gcc (GCC) 4.1.1 20060524 |
| Compilation | Program compiled with variations of the
following compilation flags: CFLAGS := -g -Wall -Werror -std=c99 -O3 -mcpu=440 -mfpu=dp_full |
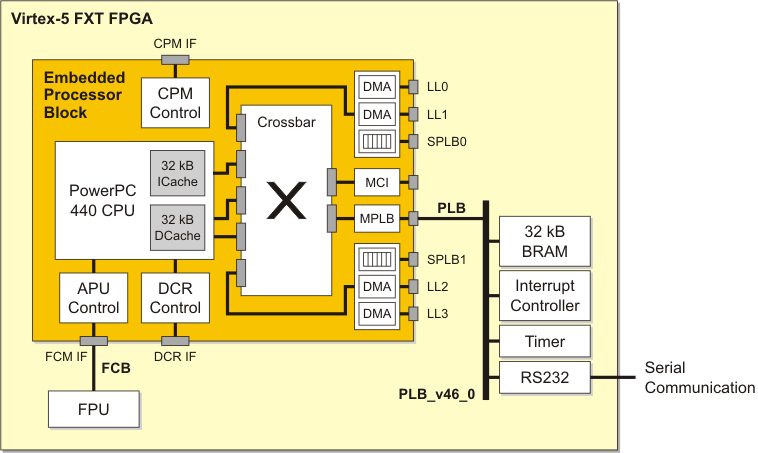
The hardware architecture is depicted below. Only essential peripheral blocks have been attached to the CPU.
|
| Hardware architecture for the performance assessment of the embedded IBM PowerPC 440 CPU using the Whetstone benchmark. A double-precision floating point unit (DP-FPU) as soft IP block clocked at 200 MHz has been connected through the fabric coprocessor bus (FCB) to the CPU core running at 400 MHz. As peripheral blocks, 32 kB on-board memory, timer, interrupt controller and RS232 UART for serial communication are connected. |
The clocking scheme of the system architecture needs to adhere
to a bunch of different rules imposed by various interconnect and
device specifics. The applied clocking scheme and the
corresponding important clock ratios are listed below.
| Clock | Frequency | Clock Ratio |
| CPU core clock | 400 MHz | |
| FCM clock (APU) | 200 MHz | CPU:FCM 2:1 |
| CPM clock | 133 MHz | CPU:CPM 3:1 |
| MPLB (PLB_v46_0) | 133 MHz | CPU:MPLB 3:1, CPM:MPLB 1:1 |
| APU | Auxiliary Processing Unit |
| BRAM | Block Random Access Memory |
| CPM | Communications Processor Module |
| DAC | Digital-to-Analog Converter |
| DCR | Device Control Register |
| DMA | Direct Memory Access |
| FCB | Fabric Coprocessor Bus |
| FCM | Fabric Coprocessor Module |
| FPU | Floating-Point Unit |
| GPIO | General Purpose Input/Output |
| MCI | Memory Controller Interface |
| MPLB | Processor Local Bus Master |
| SPLB | Processor Local Bus Slave |
| PLB | Processor Local Bus |
| PPC | PowerPC |
The Whetstone benchmark is a synthetic benchmark initially composed in 1972 using the Algol 60 programming language [3]. Later on, the source code of the benchmark was ported to FORTRAN and C [4, 5]. The Whetstone benchmark intends to qualify the CPU performance by employing various CPU-centric operations within approx. 150 code statements. The benchmarks itself performs a number of iterations on a set of modules. Each module performs a loop on certain instructions such as procedure calls, branching statements, fixed- and floating-point arithmetics, and trigonometric operations - with a predefined weighted amount of executions for each loop derived from the initially specified number of iterations. The dominant code section usually accounts for 30%-50% of execution time and performs floating-point operations [4]. As stated in the code, a loop number of 10 corresponds to one million Whetstone instructions. By specifying the loop number and by measuring the overall execution time of the benchmark on a given CPU, the individual CPU performance can then be reflected in a benchmark-specific metric called Million Whetstone Instructions per Second (MWIPS).
In general, a synthetic benchmark like Whetstone has to
satisfy contradicting design requirements [3]:
On one hand, the benchmark must be simple enough to be easily
portable from one machine to another and to be translated to
different programming languages. On the other hand, the benchmark
has to exhibit sufficient complexity as to represent a sound
measure for CPU performance without inferring language-specific
peculiarities, while at the same time preventing excessive
compiler optimizations. According to [3], at
design time of the Whetstone benchmark, code movement out of
loops and similar extensive optimization techniques were rarely
performed by ALGOL 60 compilers, hence procedure calls and loops
were viable techniques when confined to the ALGOL 60 programming
language.
Citing Roy Longbottom's [4] interesting
statement
about compiler optimizations attributed to the Whetstone
benchmark:
"The code was designed to be non-optimisable and optimising compilers did not have a significant impact until the introduction of in-lining of subroutine instructions. Although this produces code outside the definition of Whetstone instructions, which include a specific proportion of procedure calls, it is a valid technique to obtain the best performance out of modern systems and may well be the compiler default optimisation level. As reflected in the PC results, a good compiler can halve the execution time by in-lining, careful choice of instructions and sequence, and omission of intermediate stores/loads.
With in-lining and global optimisation, a small number of
compilers identified that the dominant loop did not have to be
executed and immediately lead to an apparent more than doubling
of MWIPS speeds. This was identified by the 1980 enhancements and
fixed in 1987, essentially by changing the name of one variable.
Unlike some other standard benchmarks, Whetstone results were
generally verified as part of the Central Computer and
Telecommunications Agency (CCTA) system appraisal, in project
related benchmarking sessions or during acceptance trials. It was
also standard practice to run the tests with different levels of
optimisation and obvious over - optimised results were not
published."
Selected tests with absent floating-point unit (FPU) employ the compilation flag '-mppcperflib' which infers the IBM PowerPC Performance Libraries for optimized low-level integer and floating-point emulation, and optimized string handling routines [6]. According to Xilinx, the IBM PowerPC Performance Libraries may show an average of three times increase in speed on applications that heavily use these routines.
Caution: The IBM PowerPC Performance Libraries are only
intended for improving the execution of emulated floating-point
arithmetics and hence cannot be used in conjunction with
floating-point hardware, i.e., with active '-mfpu'
switch.
The source code has been compiled using GCC wit compiler flags
indicated below.
Any interpretation is left to the prospective reader.
IBM PowerPC 440 @ 400 MHz with dedicated double-precision FPU @ 200 MHz
The gray shaded table entries represent compiler settings violating the intended compilation rules of the synthetic benchmark.
| Compiler optimization flags | -O3¹ | -O2² | -O1³ |
| Execution time for 400'000 loops [s] | 83.8 |
296.9 |
310.4 |
| Million Whetstone instructions per second (MWIPS) | 477.2 |
134.7 |
128.9 |
| Time for one loop through Whetstone
[us] |
210 |
742 |
776 |
| MWIPS/MHz | 1.19 |
0.34 |
0.32 |
IBM PowerPC 440 @ 400 MHz without dedicated FPU, using software-emulated floating-point
The gray shaded table entries represent compiler settings violating the intended compilation rules of the synthetic benchmark.
| Compiler optimization flags | -O3 -mppcperflib¹º | -O3¹¹ | -O2 -mppcperflib²º | -O2²¹ |
| Execution time for 100'000 loops [s] | 75.8 |
211.3 |
283.2 |
673.4 |
| Million Whetstone instructions per second (MWIPS) | 131.9 |
47.3 |
35.3 |
14.9 |
| Time for one loop through Whetstone
[us] |
758 |
2113 |
2832 |
6734 |
| MWIPS/MHz | 0.33 |
0.12 |
0.09 |
0.04 |
PPC w/ FPU, using 134.7 MWIPS @ 400 MHz as
reference data:
| CPU clock [MHz] | 100 | 200 | 300 | 400 | 500 | 550 |
| MWIPS | 34 |
67 |
101 |
135 |
168 |
185 |
| MWIPS/MHz | 0.34 |
|||||
PPC w/o FPU, using 35.3 MWIPS @ 400 MHz as reference data:
| CPU clock [MHz] | 100 | 200 | 300 | 400 | 500 | 550 |
| MWIPS | 9 |
18 |
26 |
35 |
44 |
49 |
| MWIPS/MHz | 0.09 |
|||||
By using an embedded PowerPC 440 CPU running at 400 MHz in conjunction with a double-precision floating-point unit running at 200 MHz, a Whetstone performance of 135 MWIPS was measured with cache-adjusted code size and compiler settings not violating the rules of the benchmark. Extrapolated to the fastest available Virtex-5 FPGA speed grade (i.e., a CPU clock frequency of 550 MHz), the PowerPC 440 would achieve 185 MWIPS for the version 1.2 benchmark.
When using a PowerPC 440 CPU running at 400 MHz without dedicated FPU coprocessor, all floating-point arithmetics have to be performed by software. In this context, a Whetstone performance of 35 MWIPS was measured by inferring the IBM PowerPC Performance Libraries during compilation. Without inferring the PowerPC Performance Libraries, the Whetstone performance of the employed system decreases to merely 15 MWIPS.
However, the relevance of these performance numbers are in general questionable: The code must be running entirely from cache without any I/O transfers to show best results. As soon as larger code size, costly I/O transfers, and different compiler options are involved, these numbers are merely theoretical.
Last but not least, it is very impressive to see how different
code optimization techniques of the compiler significantly
influence the execution time of the identical piece of code. Here
at last it becomes obvious, that a CPU performance measuring tool
like a benchmark needs to be designed by keeping clearly in mind
hardware, software and compiler architectures and
capabilities.
[1] Xilinx Inc., Virtex-5 Family Brochure, Dec 2008
[2] Xilinc Inc., Virtex-5
Website
[3] H.J. Curnow, B.A. Wichmann, "A synthetic benchmark" (Whetstone), Computer Journal, Vol 19, No 1, pp 43-49, 1976
[4] Roy Longbottom, Whetstone
Benchmark History and Results
[5] netlib.org, Benchmark Programs and Reports
[6] sourceforge.net, IBM PowerPC Performance Libraries
Last updated: 2012/12/30